



Enforce data governance and structure to prevent chaos in your Unified Namespace.

Transform and contextualise raw data on the fly using intelligent models and pipelines.
Easily integrate with other high-end tools to serve as your central intelligence layer.

HighByte Intelligence Hub is an Industrial DataOps platform, designed specifically for industrial data modelling, orchestration, and governance.
It acts as an intelligence layer in your factory data architecture, sitting between your OT systems and the applications that consume data.
It is an edge-native, no-code solution that securely collects, models, and delivers payloads to target applications across your enterprise.
Where most connectivity tools focus on moving data from A to B, HighByte adds a dedicated layer to model, standardise, and contextualise that data before it reaches its destination: a Unified Namespace, historian, cloud platform, or analytics application.


We position HighByte in architectures where clients need advanced, enterprise-grade data intelligence alongside a best-of-breed approach. For example, you could use Ignition for its broad device connectivity, and layer HighByte on top to handle the modelling and governance before data enters the wider architecture.
HighByte also has a native integration into Inductive Automation’s Ignition platform, which makes it a natural fit for the projects we run. It is especially relevant in complex Unified Namespace deployments where multiple teams feed data into a shared broker, and a governance layer that enforces schemas is essential.
The same logic applies when combining HighByte with Tulip. Tulip digitises the operator layer on the shop floor, and HighByte sits in between, contextualising and governing data in both directions. It routes operator data upstream into the UNS and feeds contextualised data back down into Tulip apps.


Building a complex, enterprise-grade data architecture? Here’s why HighByte Intelligence Hub is worth considering.
HighByte lets you build models that standardise and contextualise raw data points, set up data pipelines, and enforce governance through rules. It normalises variables across different machines to overcome inconsistent device structures.
You can also apply logic, deadbands, and calculations on the fly to reduce noise and transform raw inputs. That way, you can be sure that your data is fully contextualised before it ever reaches your database or AI models.
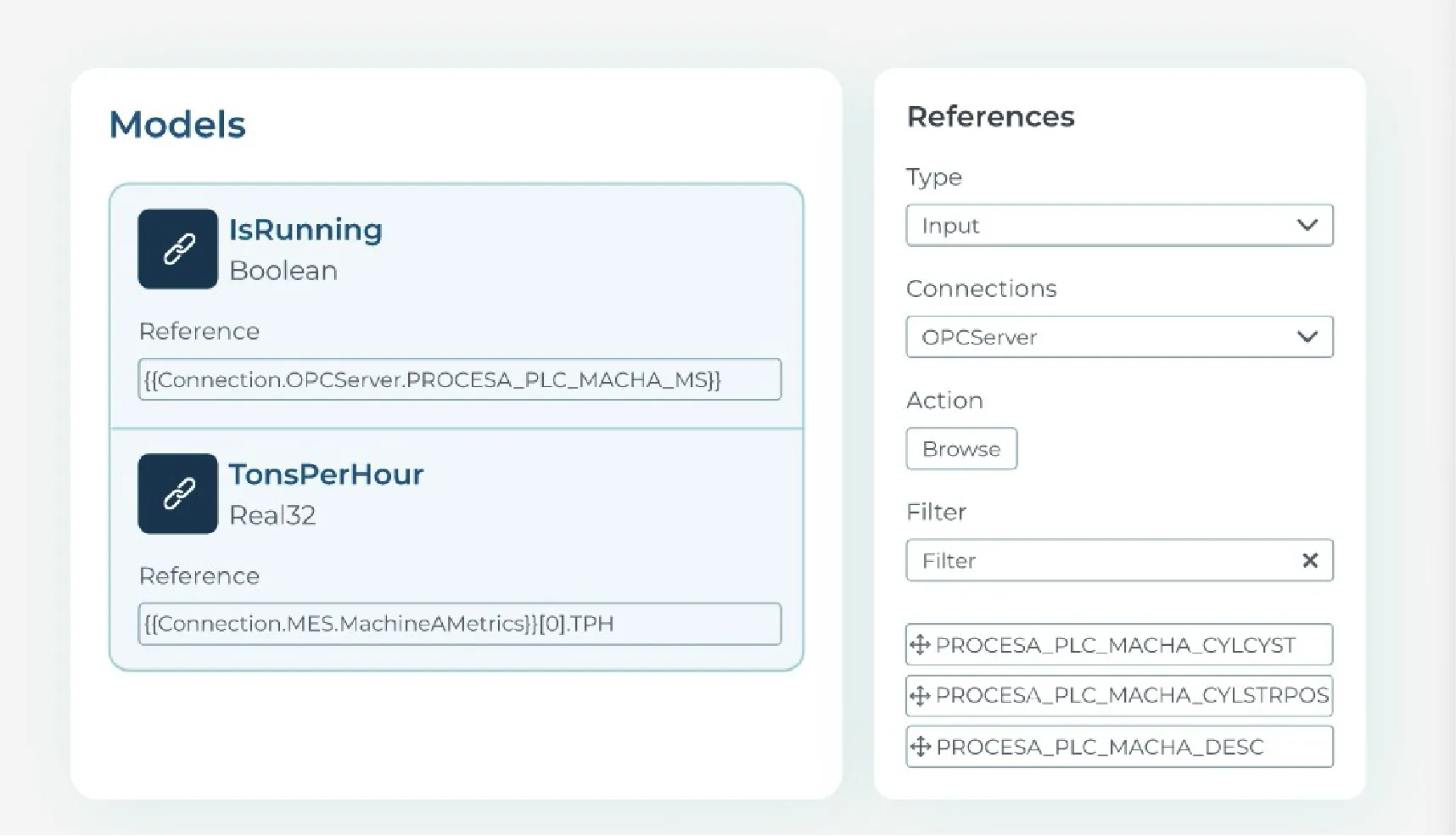
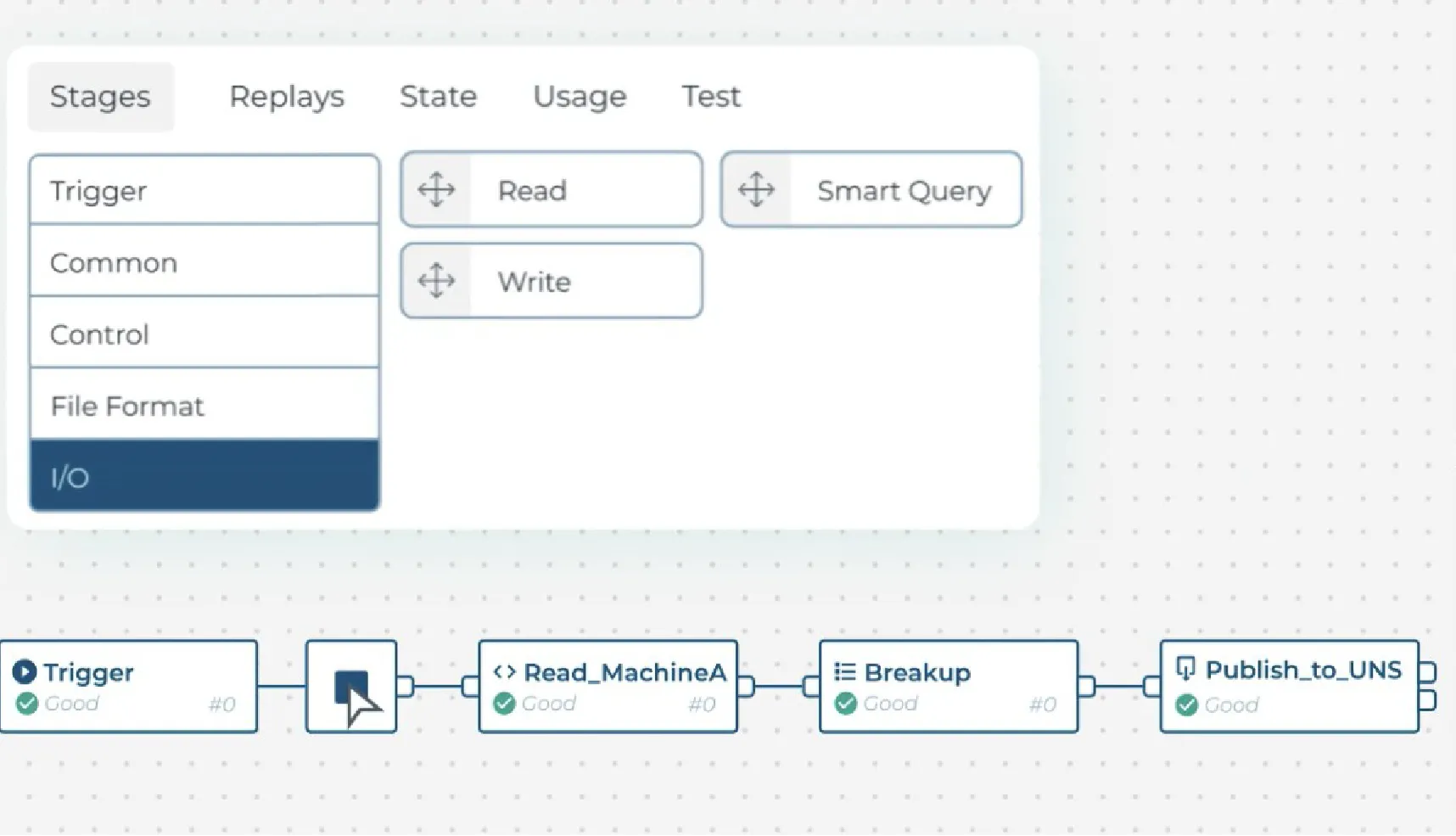
HighByte eliminates the need for custom code or troubleshooting broken integrations. You can use its graphical interface to build pipelines that filter, buffer, and transform payloads specifically for the system consuming them.
With native connections to tools like Ignition, MQTT brokers, AWS Snowflake and TimescaleDB, you can route data between your OT and IT layers without writing a single line of custom integration code.
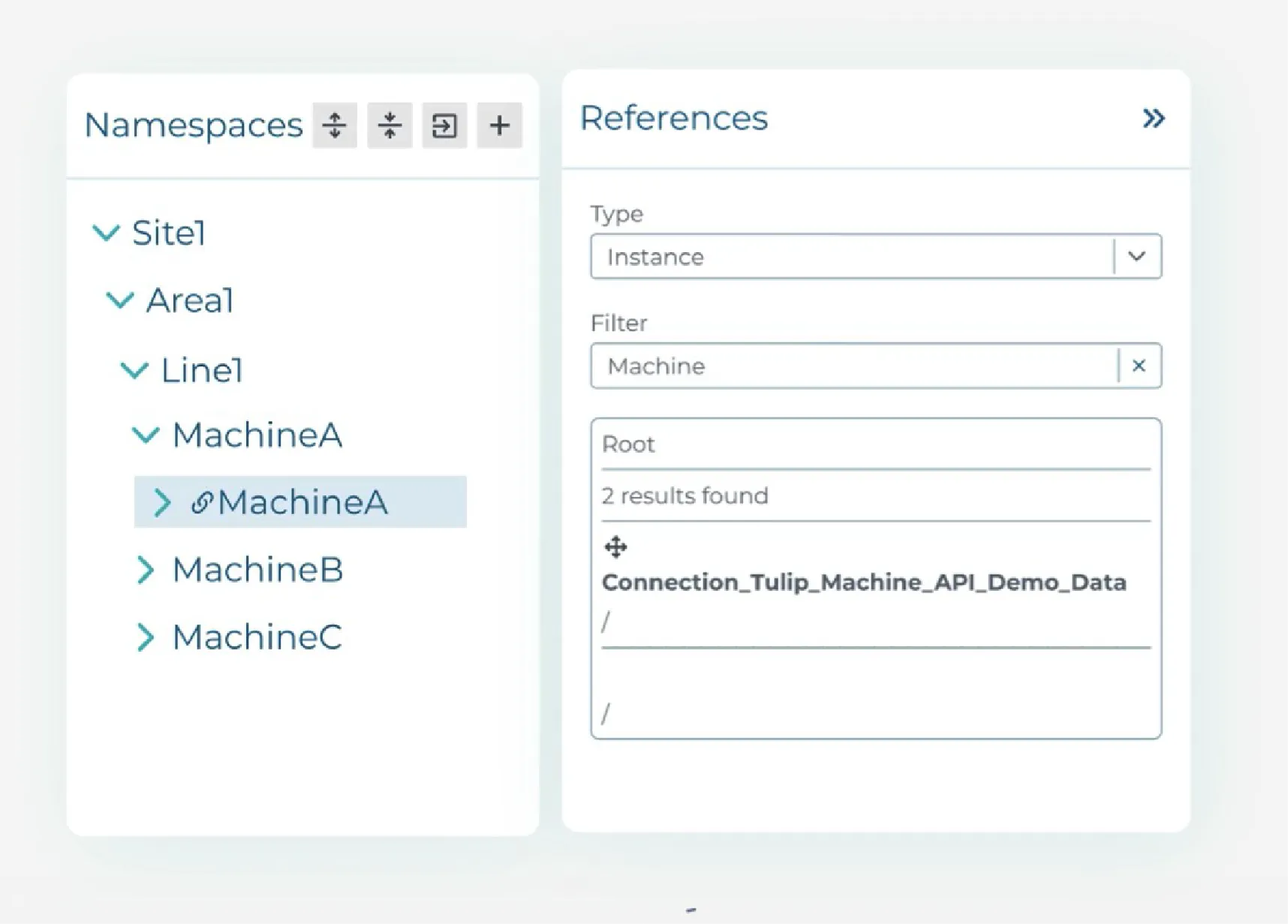
If you are rolling out a Unified Namespace (UNS), HighByte can act as your central command. Its dedicated Namespaces feature and Smart Query functionality give you a visual space to design and enforce your data hierarchy.
You can run queries across the entire namespace, and verify that every data point follows your organisation’s structural rules before it hits the enterprise broker.
For regulated industries like life sciences and utilities, HighByte has a dedicated High Availability mode. In this mode, Intelligence Hub continuously synchronises both configuration and state across runtimes through a shared PostgreSQL database. When a primary hub becomes unavailable, the secondary hub will assume control with full awareness of the latest configuration and pipeline activity.
Combine High Availability Mode with other features like built-in auditing, role-based access, and Git integration for version control, and you get the traceability and security required for heavily regulated environments.
Recently, HighByte introduced an embedded Industrial MCP Server, which exposes data pipelines as tools for AI agents. AI agents can use this to securely access all connected systems and make real-time or historical data requests directly through the Intelligence Hub.
Intelligence Hub also supports LLM-assisted data contextualisation via native connections to Amazon Bedrock, Azure OpenAI, and Google Gemini, which significantly accelerates the modelling work for large deployments. If you’re looking to use AI securely, we recommend checking it out.

HighByte offers a free trial of the Intelligence Hub. It is easy to install on lightweight hardware (Windows, macOS, or Linux) or you can simply deploy it as a Docker container.
The trial resets every two hours, but you can restart it an unlimited number of times. Once you are ready to move beyond testing, we are here to help you integrate it securely.

Download our free MQTT broker tester and find out if your MQTT infrastructure is production-ready.

Industrial DataOps can be difficult to wrap your head around at first, but HighByte’s Resource Hub offers excellent guides and materials on both their own product and DataOps in general.
We recommend taking a look at the following resources in particular:










